Dialogue analysis of Connor from AO3 D:BH fics
This is something that I’ve been working on for a while. I’m still not done with this and this is really exploratory stuff, but decided to force myself to write up something lest it simply rots on my hard drive (with all my other unfinished fanwork).
This work is sort of related to my earlier one on trying to understand fanon representations of characters from story tags. One limitation of that work is that it relied solely on author-provided tags. And we know that tags usually don’t give the whole picture of what the characters are like – it’s impossible to tag every nuance of all the people you’ve written.
Since fanfiction is mostly still a text-only medium, I supposed that a character is portrayed, through the author’s writing, via (1) the words they speak and (2) the actions they do. This current write-up covers my chicken-scratch so far on the words spoken bit; I’m still currently working from zero on the actions bit. The questions driving the analyses I tried to do here are:
- Are certain words in Connor’s fanfic dialogue more associated with one rating over another? (correspondence analysis – section 2)
- How similar are Connor’s fanfic utterances to his canon utterances? (cosine similarity via embeddings – section 3)
- Are Connor’s fanfic dialogue utterances possibly separable by rating? (UMAP visualisation with embeddings, followed by actual clustering on embeddings – sections 4 and 5)
As usual, if you’re here from my Tumblr looking for (all) the interactive images, here they are (though I do recommend reading the long write-up, since the focus is more on the process than results this time): asymmetric biplot of dialogue unigrams, canon/fanon Connor dialogue cosine similarity distributions by fic rating, UMAP embeddings of extracted dialogue coloured by fic rating, cluster-space of extracted dialogue coloured by fic rating, and clusters of extracted dialogue.
To re-emphasise, this page is a WIP. I approach the problem very naively and hope to update it in the future.
Content
1) Preprocessing with BookNLP
2) Correspondence analysis of dialogue unigrams
3) Similarity between canon and fanon dialogue
4) Visualising dialogue by fic rating
5) Clustering dialogue embeddings
6) Conclusion
Preprocessing with BookNLP
Before going further, I really want to give huge thanks to BookNLP – if you’re interested in NLP and working with books/book-length documents, definitely do check this library out. This whole series of analyses wouldn’t be possible to start without it. Prior to using this library, I was just trying to naively pluck out dialogues with scrappy regex and was unable to handle coreference resolution well at all.
I cleaned and ran the fics through BookNLP, which returns identified entities (with coreference resolution), quotes with their speakers identified, and event tagging, among other things. One thing to note, however, is that BookNLP was trained on published English fiction literature. Think of books like The Life and Adventures of Robinson Crusoe, Ulysses, and The Picture of Dorian Gray. We can imagine that many fanfics don’t follow the style of such books (mine don’t, at least) – in terms of literary style, and perhaps more importantly, specifically in terms of formatting of dialogue and speech patterns. This means that we can expect some noticeable degree of error in dialogue retrieval and dialogue speaker attribution when applying a model trained in that domain to the fanfiction domain.
After finishing running everything through BookNLP (it takes a while, understandably), I did spot errors. It wasn’t uncommon for dialogue quotes to be cut off halfway, or to run over into areas where the dialogue has already ended, and the writer has gone back to describing the scene (adapted example: ” Another stab at his pride. “You). I dealt with this by keeping only extracted snippets that started and ended with double quotes.
As this analysis is focused only on Connor, I only kept quotes that were attributed to Connor. Again, as BookNLP provides coreference resolution, it points out quotes that are attributed to a pronoun which may tie back to Connor (e.g., certain ‘he said’s may be something Connor said). Thus, I was able to keep these quotes too. Coreference resolution and speaker attribution are still terribly difficult problems though, so I did spot errors here as well (e.g., Hank’s speech being attributed to Connor). I couldn’t think of a good way to automate the cleaning of these out at this point, so I left them in my dataset. We’ll see later, though, that visualising/clustering dialogue embeddings may help point out dialogue actually spoken by other characters, that were mistakenly identified as Connor’s. I retrieved 289,009 lines of Connor dialogue from 8,055 fics.
Correspondence analysis of dialogue unigrams
I’ve done a more in-depth write-up of correspondence analysis (CA) some time back, which looked at the association between Drarry freeform tags and fic ratings. So, I won’t be running through all the steps I took there.
Here, I use CA to look at the association between unigrams (i.e., singular words) in the extracted Connor dialogue and fic ratings. I use the full set of 289,009 lines of Connor dialogue extracted.
Preprocessing
I tokenised each Connor dialogue and kept words that matched the following conditions: (1) longer than 1 letter, (2) wholly alphabetic, (3) not in a list of stopwords. As there may be many rare words, I kept only the top 500 words for this analysis. I think this selection of words can be improved on.
Correspondence analysis
A Pearson’s chi-squared test returns a significant result, showing that there is a significant association between the dialogue unigrams and fic ratings. I thus proceeded with CA.
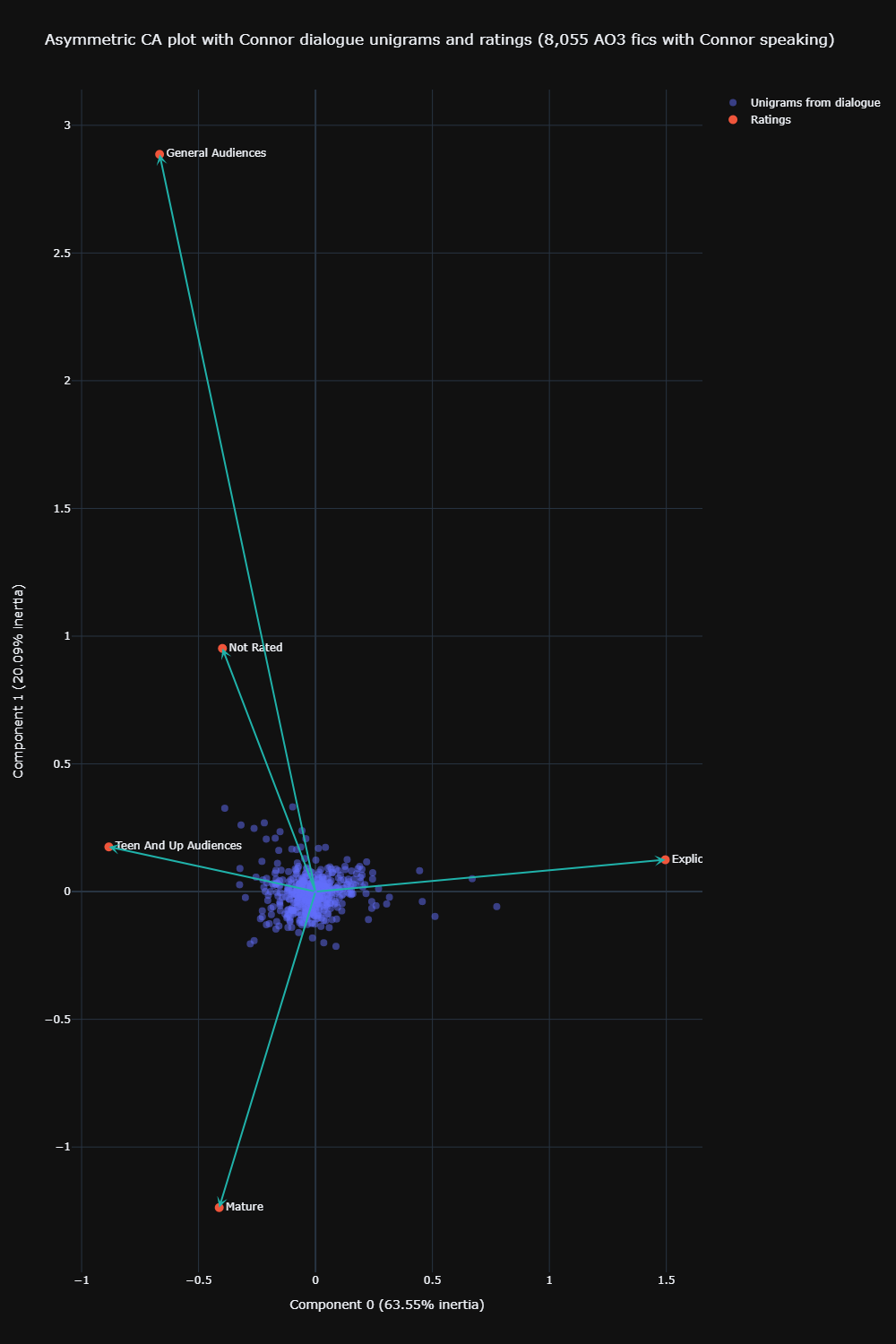
The variance explained by the first dimension in CA is 63.5%, and by the second is 20.1%. That is pretty sizeable. However, the eigenvalues for both dimensions are weak, at 0.01 and 0.003. This means that many unigrams are not exclusive to specific ratings. This is to be expected somewhat, as what makes an explicit utterance isn’t exactly the usage of one word many times, but the way words are combined together.
This idea becomes clearer when we look at the asymmetric biplot. Here, I chose the ‘colprincipal’ option, which represents the ratings in unigram space.
Click here for the interactive version
We can see that most unigrams are just clustered very tightly around the origin, which means they aren’t particularly distinctive of any rating.
As I mentioned in my previous post on CA, we can judge the strength of association between a certain unigram and a certain rating using this asymmetric biplot. Imagine that each unigram also had an arrow pointing to it, beginning from the origin. If the angle between that arrow and the arrow of a certain rating is acute, then there is a strong association between that unigram and that rating. For example, ‘baby’ has a strong association with explicit fics, and ‘investigate’ with mature fics.
I’d like to add at this juncture too that I’m liking how, over multiple analyses, evidence seems to be coalescing around the idea that explicit fics are tagged as such for sexual reasons, whereas mature fics are more likely tagged as such for serious themes like mental health, or darker themes like crime. Of course, these are not mutually exclusive themes, but there at least seems to be some observable trend.
Similarity between canon and fanon dialogue
Besides wanting to find ways to summarise how writers have characterised characters in fanfiction, I am also interested in finding ways to quantify the distance between the fanfiction and canon character(s).
This is quite difficult to do with D:BH admittedly, as D:BH is foremost a video game. Currently, my only access to canon Connor is through the text lines provided by Detroit: Become Text. However, Connor also demonstrates his personality in-game via his facial expressions, voice tone, and so on. In my mind, I think it may be easier to start with a character that came from a text-medium foremost (so their dialogue, actions, expressions are all written down), so I’m thinking of redoing and furthering this analysis sometime using Harry Potter and Draco Malfoy (books versus fanfiction).
For now, I’ll write a little about the frankly very weak analysis I’ve done for Connor, given the data I have. The idea is to find the average distance between canon Connor dialogue, and the Connor dialogue that was extracted from the fics. Clearly this is no way to conclude my question of how far or near fanfiction Connor is from canon Connor. I see this as just one small starting point on a path to answer that question more fully.
To run this analysis, I selected only dialogue (canon/fanfiction) that had 10 to 24 words. This covers the 25th to 90th percentile of canon Connor utterance length, and 70th to 90th percentile of fanfiction Connor utterance length. I did this as a rough heuristic to try to keep utterances where Connor was talking about something (i.e., not just a cry of pain, etc). This was also to keep dialogue bits around the same length, as I was converting all these bits to MPNet embeddings (trying without any cut-offs gave somewhat strange results).
This left me with 72,860 utterances from fanfiction Connor (again, remember I mentioned that not all of these may be Connor, due to errors that will undoubtedly occur during the extraction process) and 386 utterances from canon Connor.
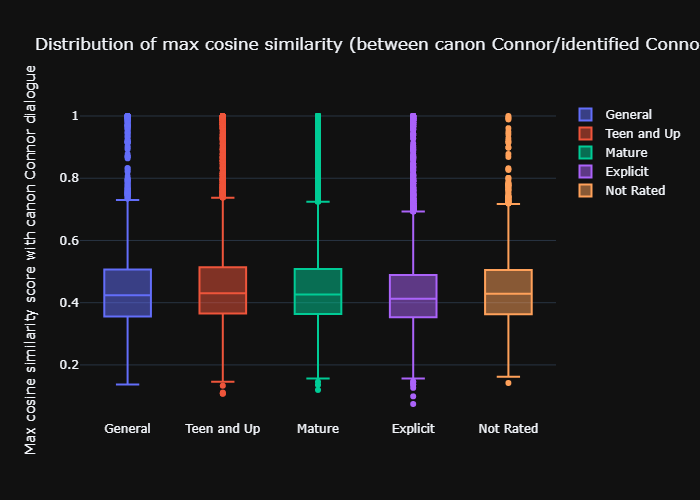
After getting the embeddings, I calculated the cosine similarity between each of the 72,860 fanfiction utterances against each of the 386 utterances. As expected, multiple fanfiction utterances are taken word-for-word from canon (e.g., the infamous ‘My name is Connor. I’m the android sent by Cyberlife). I then kept the max cosine similarity score for each of the 72,860 utterances against the canon utterances (so, 72,860 scores). Then, I broke down the scores by rating, hoping to answer the question – are Connor utterances from gen/teen/mature fics closer to canon Connor utterances semantically, than explicit fics?
Here you can find the plotted distribution:
Click here for the interactive version
We can see that there isn’t a huge obvious difference between the ratings. If anything, explicit fic utterances are a little lower on the similarity to canon utterances, but it doesn’t look that much convincingly lower.
I tested this more formally with a Kruskal-Wallis test with posthoc Dunn’s tests to check for pairwise comparisons. In terms of mean ranks, explicit<general audiences<not rated<mature<teen and up. That means that teen and up fic utterances are overall closest to canon utterances, followed by mature, and so on. There were significant differences between explicit fic utterances versus all the other ratings, general audiences with teen, mature and teen, and not rated and teen.
So the answer to the question of whether Connor utterances from gen/teen/mature fics are semantically closer to canon Connor utterances, than explicit fics is a yes, statistically, but the boxplot showed very little visible difference. And the plot doesn’t lie, when calculating the effect size for the Kruskal-Wallis test, we find a very small effect size (eta-squared is used here) – 0.004. Hence, yes, we may have found a statistical difference, but practically speaking, that difference is very, very small.
Visualising dialogue by fic rating
Next, I wanted to know if fanfiction Connor’s utterances were possibly separable by fic rating. I used the filtered set of 72,860 fanfiction Connor utterances, which were 10 to 24 words in length. I had a hunch that the answer would be close to no, especially given the weak CA results.
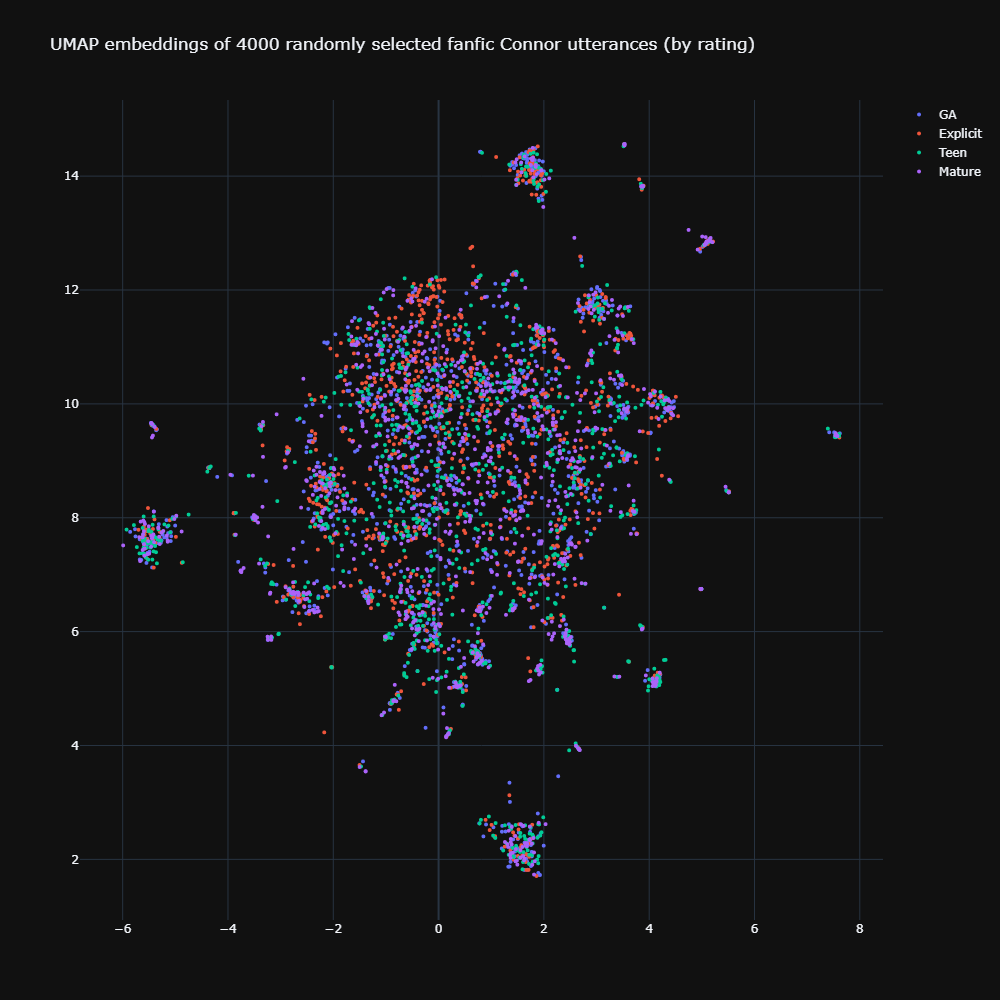
Before jumping into clustering, I started by visualising the 768-dimension MPNet embeddings in a 2D space with the help of UMAP (n_neighbors=15). I selected 1000 random utterances by rating (making 4000 in total) to visualise. Rerunning this visualisation with different selections of 4000 utterances does not drastically change its overall shape and appearance.
Here is one of the visualisations:
Click here for the interactive version
Regarding the general patterning of points, there are no discernible clusters in the middle, though we do see a few obvious clusterings along the sides of the main hairball. Hovering over these show that they’re probably clustered due to a character name (e.g., Sumo, Gavin, Hank). And we also see that the furthest left cluster, which is probably lumped together due to mentions of ‘Connor’, looks like part of the mistakenly-attributed dialogue. E.g., “I’m so sorry, Connor, so sorry… you are a deviant right?” is really probably said by someone else other than Connor himself. Exploring other parts of the hairball also shows that proper extraction and attribution is still a ways to go on this dataset.
Looking at patterning by rating, we see that there really doesn’t seem to be any visible separation by rating at all. The ratings kind of overlay on each other on the same messy patterning. This is not to say that ratings have no influence on how dialogue is written at all. In fact, I think this result simply shows that embeddings alone are far from sufficient to capture that influence. Embeddings can help us capture semantically similar utterances to some degree, but they lack the higher-order understanding still that we as readers/writers get when we recognise something as an innuendo versus something that is plainly stated, for example. Furthermore, snippets of dialogue alone lack a lot of context – “I detect an increase in your heart rate and body temperature” for example, wouldn’t be out-of-place in both General Audience or Explicit fics. However, the intention behind it is only clear when we read it in terms of what else the character has said, or has done.
Clustering dialogue embeddings
We’ve already seen that there doesn’t appear to be any visible clustering using UMAP. I decided to check this more directly with the community detection function from the Sentence-Transformers library. I set the minimum size for a cluster to be 10 and the minimum threshold for cosine similarity within a cluster of embeddings to be 0.6. Again, I used the filtered set of 72,860 fanfiction Connor utterances, which were 10 to 24 words in length. This algorithm doesn’t require an input number of clusters and it returned 381 clusters. Some of the sentences didn’t hit the minimum 0.6 threshold for inclusion to any cluster and were dropped. The following visualisations hence show 11,145 fanfiction Connor utterances.
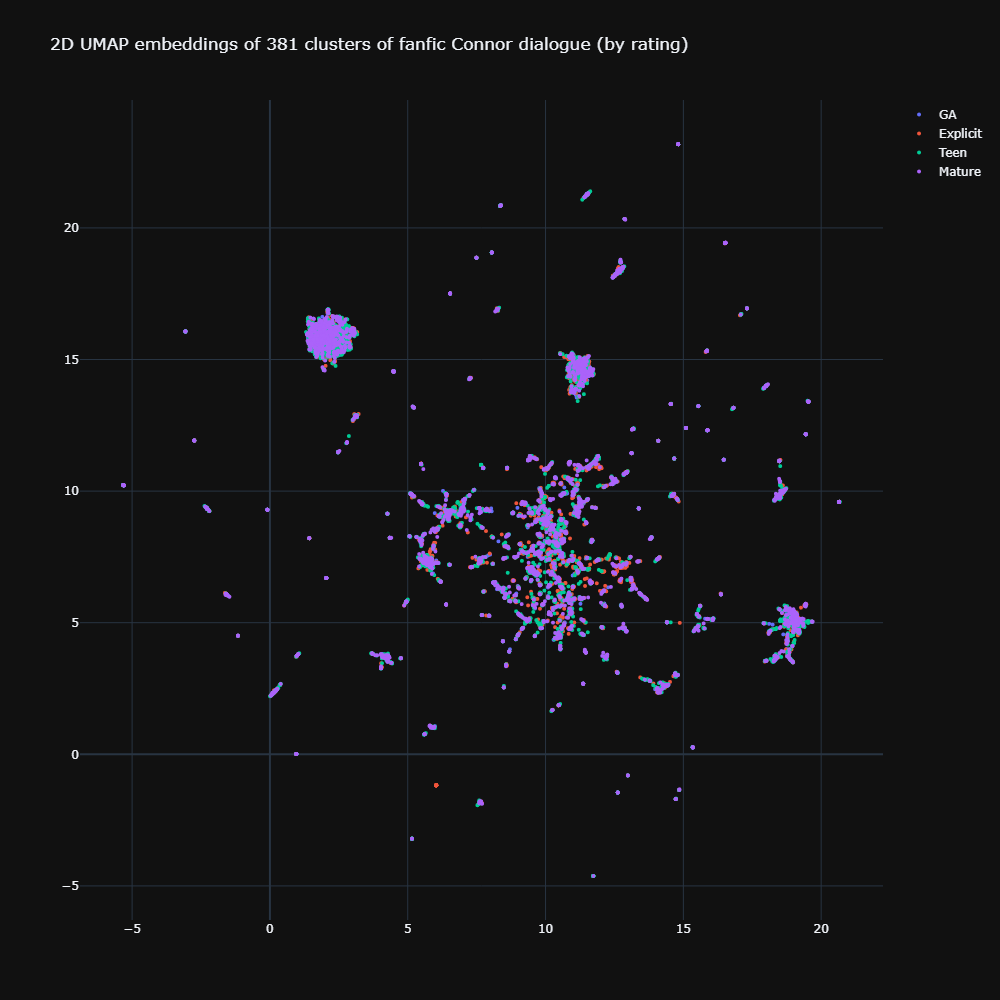
With the remaining 11,145 utterances, I resubmitted them for 2D UMAP visualisation.
Here is the resulting visualisation, coloured again by rating:
Click here for the interactive version
We notice two things. One, that big ball on the left, which again looks like mis-attributed Connor utterances. Second, for most part, the ratings kind of overlay on top of each other again, as we saw in the partial visualisation of the fuller 72,860 utterance set.
Now let’s look at the actual results of the clustering.
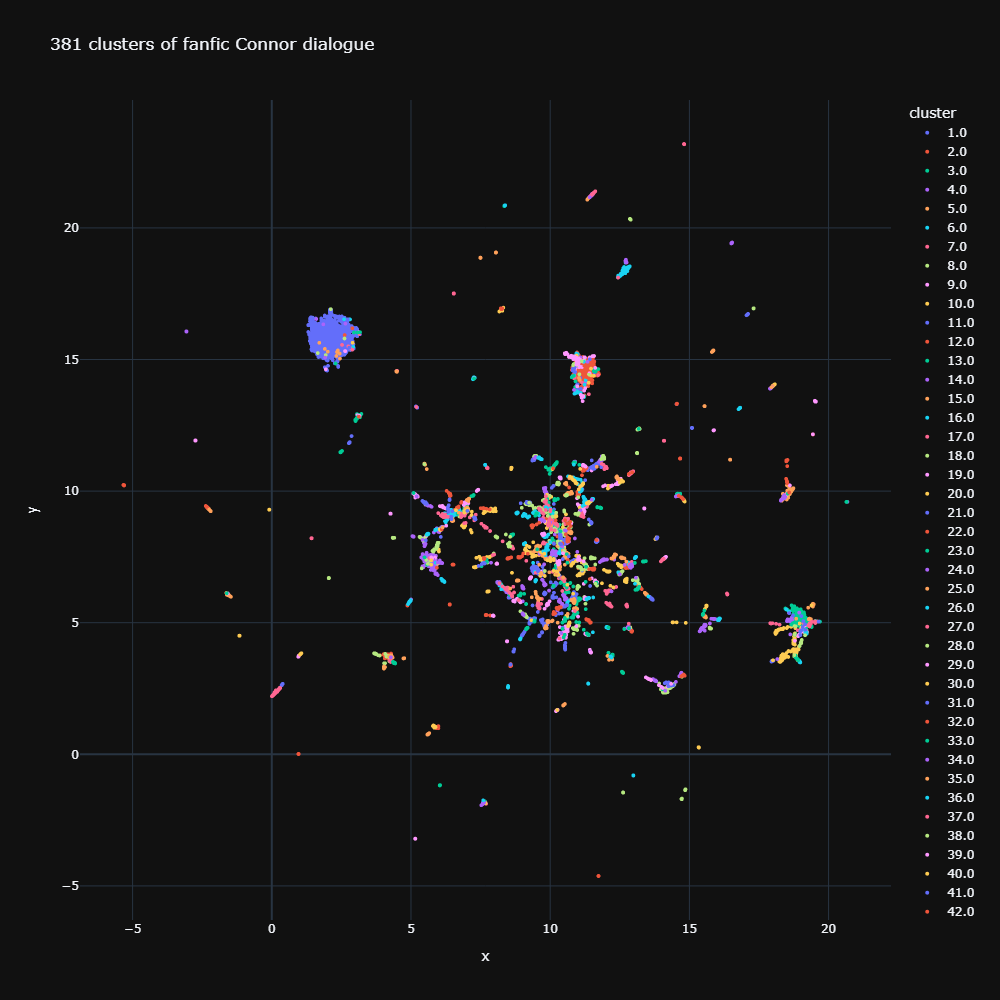
Click here for the interactive version
Clicking through the clusters show that the embeddings actually do a great job of capturing semantically similar sentences. However, as I mentioned earlier, the snippets alone don’t give us enough context to work out which rating they are from. We also notice a few clusters (Cluster 1 especially), are made up of largely misattributed Connor utterances. So perhaps I could use this clustering as a preprocessing step for future improved work.
Conclusion
And that’s what I’ve done for dialogue so far. I’m interested to extend this with Drarry fics, and so I might start a scrape for that once I have time. Attempting to cluster on the embeddings has also pointed out a glaring blind-spot I didn’t notice, which is that I’ve basically shaved off all the important context that makes an explicit utterance explicit, and a benign one benign. I’d like to work on improving that.
Currently, I’m also working on extracting character interaction networks from fics, and furthering the earlier work I did on character descriptions in tags by looking at character descriptions within fic text. I should also probably eventually start playing around with the comment data…